


Be part of our each day and weekly newsletters for the newest updates and unique content material on industry-leading AI protection. Study Extra
Whilst massive language and reasoning fashions stay widespread, organizations more and more flip to smaller fashions to run AI processes with fewer power and price issues.
Whereas some organizations are distilling bigger fashions to smaller variations, mannequin suppliers like Google proceed to launch small language fashions (SLMs) as an alternative choice to massive language fashions (LLMs), which can price extra to run with out sacrificing efficiency or accuracy.
With that in thoughts, Google has launched the newest model of its small mannequin, Gemma, which options expanded context home windows, bigger parameters and extra multimodal reasoning capabilities.
Gemma 3, which has the identical processing energy as bigger Gemini 2.0 fashions, stays greatest utilized by smaller units like telephones and laptops. The brand new mannequin has 4 sizes: 1B, 4B, 12B and 27B parameters.
With a bigger context window of 128K tokens — in contrast, Gemma 2 had a context window of 80K — Gemma 3 can perceive extra data and sophisticated requests. Google up to date Gemma 3 to work in 140 languages, analyze pictures, textual content and quick movies and assist operate calling to automate duties and agentic workflows.
Gemma offers a powerful efficiency
To scale back computing prices even additional, Google has launched quantized variations of Gemma. Consider quantized fashions as compressed fashions. This occurs by way of the method of “lowering the precision of the numerical values in a mannequin’s weights” with out sacrificing accuracy.
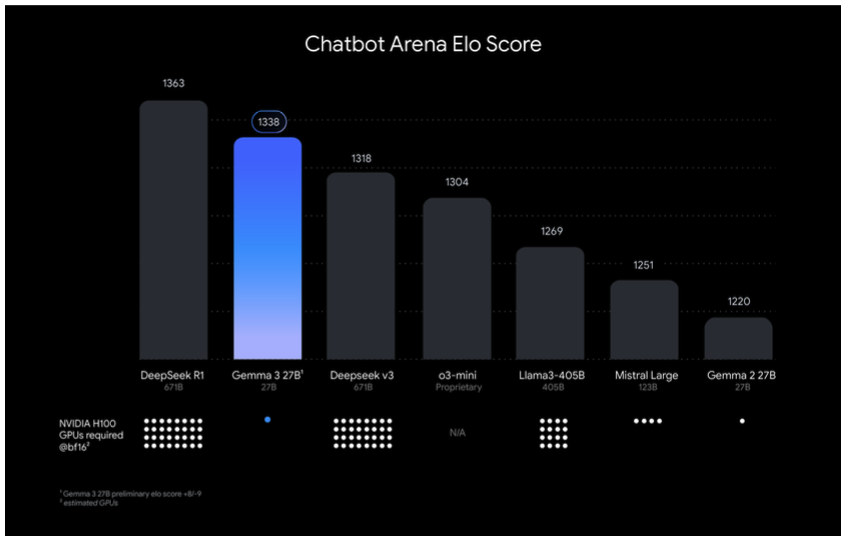
Google stated Gemma 3 “delivers state-of-the-art efficiency for its measurement” and outperforms main LLMs like Llama-405B, DeepSeek-V3 and o3-mini. Gemma 3 27B, particularly, got here in second to DeepSeek-R1 in Chatbot Area Elo rating checks. It topped DeepSeek’s smaller mannequin, DeepSeek v3, OpenAI’s o3-mini, Meta’s Llama-405B and Mistral Massive.
By quantizing Gemma 3, customers can enhance efficiency, run the mannequin and construct purposes “that may match on a single GPU and tensor processing unit (TPU) host.”
Gemma 3 integrates with developer instruments like Hugging Face Transformers, Ollama, JAX, Keras, PyTorch and others. Customers can even entry Gemma 3 by way of Google AI Studio, Hugging Face or Kaggle. Firms and builders can request entry to the Gemma 3 API by way of AI Studio.
Defend Gemma for safety
Google stated it has constructed security protocols into Gemma 3, together with a security checker for pictures referred to as ShieldGemma 2.
“Gemma 3’s growth included in depth knowledge governance, alignment with our security insurance policies through fine-tuning and strong benchmark evaluations,” Google writes in a weblog put up. “Whereas thorough testing of extra succesful fashions usually informs our evaluation of much less succesful ones, Gemma 3’s enhanced STEM efficiency prompted particular evaluations targeted on its potential for misuse in creating dangerous substances; their outcomes point out a low-risk degree.”
ShieldGemma 2 is a 4B parameter picture security checker constructed on the Gemma 3 basis. It finds and prevents the mannequin from responding with pictures containing sexually specific content material, violence and different harmful materials. Customers can customise ShieldGemma 2 to go well with their particular wants.
Small fashions and distillation on the rise
Since Google first launched Gemma in February 2024, SLMs have seen a rise in curiosity. Different small fashions like Microsoft’s Phi-4 and Mistral Small 3 point out that enterprises wish to construct purposes with fashions as highly effective as LLMs, however not essentially use your complete breadth of what an LLM is able to.
Enterprises have additionally begun turning to smaller variations of the LLMs they like by way of distillation. To be clear, Gemma will not be a distillation of Gemini 2.0; somewhat, it’s educated with the identical dataset and structure. A distilled mannequin learns from a bigger mannequin, which Gemma doesn’t.
Organizations usually choose to suit sure use circumstances to a mannequin. As a substitute of deploying an LLM like o3-mini or Claude 3.7 Sonnet to a easy code editor, a smaller mannequin, whether or not an SLM or a distilled model, can simply do these duties with out overfitting an enormous mannequin.
